
Rejoignez-nous le 30 avril : dévoilement de Parasoft C/C++test CT pour l'excellence en matière de tests continus et de conformité | En savoir plus
Aller à la section
Mesurer la couverture du code : guide pour des tests efficaces

20 novembre 2023
10 min lire
La couverture du code dépend fortement de la précision. Il s'agit de choisir uniquement la couverture appropriée requise pour votre projet. Les deux principaux pièges de couverture de code sont discutés en détail dans cet article, ainsi que la façon de les éviter.
Aller à la section
Aller à la section
Qu'est-ce que la couverture de code ?
L'essence de la couverture de code consiste à exposer le code qui n'a pas été exécuté après avoir effectué vos tests logiciels. Le code découvert indique clairement où des défauts peuvent se cacher dans l'application et qu'il vous manque des cas de test pour traiter ces zones non couvertes.
L'approche la plus courante pour surveiller le code lors de son exécution et atteindre sa couverture consiste à instrumenter le code. Cela signifie que le code existant est enrichi de code supplémentaire et peut être personnalisé davantage pour détecter si des structures de codage telles qu'une instruction, une fonction, une condition, une décision, une branche et autres ont été exécutées. Ceci est important car il existe différentes voies logiques d’exécution qui peuvent être empruntées, vous voulez donc vous assurer que vous les avez exercées et que vous avez dénoncé un comportement dangereux, peu sûr ou imprévisible.
Avantages de mesurer la couverture du code
Vous ne voulez pas de couverture pour le plaisir. Vous avez besoin d'une couverture significative qui indique que vous avez fait du bon travail en testant le logiciel. En plus de détecter les lacunes de vos tests, la couverture du code expose également le code mort.
Le code mort est un code qui existe dans l'application, mais il n'existe aucun scénario d'exécution possible pour que ce code soit exercé. Parfois, nos exigences changent, nous modifions donc la logique. Dans les systèmes logiciels complexes, nous ne réalisons pas tous les résultats et effets, comme par exemple avoir une fonction ou une structure de code qui ne sera jamais exécutée. Par conséquent, un code mort peut indiquer un défaut de logique, mais il s’agit au minimum d’un risque de sécurité qui doit être résolu.
Il y a également des avantages pour l’utilisateur final ou la partie prenante à mesurer la couverture du code. Si l'application a été testée et que 100 % du code a été couvert, cela procure ce sentiment chaleureux et flou de fournir quelque chose de qualité, comparé à celui de fournir une application avec seulement 60 % de couverture de code atteinte. C'est également la raison pour laquelle les normes de sécurité fonctionnelle de l'industrie telles que DO-178C, ISO 26262, IEC 62304, IEC 61508, EN 50128 et bien d'autres imposent ou recommandent fortement aux équipes de développement d'effectuer une couverture du code.
Mesures de couverture du code
Les normes fonctionnelles guident également le type de mesures de couverture à atteindre et certaines des différentes méthodes de test à utiliser. Comme mentionné précédemment, il existe des structures de codage telles que des instructions, des branches, des décisions, etc., qui ne sont exercées que dans des conditions très spécifiques. Ces conditions dépendent de variables spécifiques et de leurs valeurs au bon moment.
Sur la base de conditions appropriées, les différents chemins d'exécution peuvent être suivis et des métriques collectées. Par conséquent, vous devez créer plusieurs cas de test pour alimenter l’application avec les bonnes données et créer la condition souhaitée.
Pour collecter des métriques de couverture de code, les équipes peuvent utiliser diverses méthodes de couverture de tests telles que les tests unitaires, les tests système, les tests manuels, etc.
Couverture de test
Étant donné que les équipes d'assurance qualité (AQ) doivent effectuer des tests système, de nombreuses organisations utilisent leurs scénarios de test système pour obtenir une couverture de code. Cependant, il est courant que les tests au niveau du système ne fournissent pas les objectifs de couverture requis. Il donne généralement une couverture de 60 %, ce qui laisse beaucoup de place aux problèmes non découverts. Par conséquent, les équipes peuvent finir par regrouper la couverture des tests unitaires, des tests d’intégration et des tests manuels.
Ensemble, ces méthodes de test peuvent vous permettre d'atteindre une couverture de code à 100 % ou l'objectif souhaité. Mais les organisations doivent également comprendre le niveau de couverture du code structurel requis. Les normes de sécurité fonctionnelle imposent ou recommandent que la couverture du code consiste en une couverture de déclaration, de branche et/ou de décision de condition modifiée (MC/DC). Ceci est déterminé par le niveau d'intégrité de sécurité (SIL) défini sur votre application.
Plus le risque pour les personnes et les biens en cas de panne du logiciel est élevé, plus le nombre d'ensembles de codes structurels requis est élevé. Les exigences de couverture de code les plus strictes existent dans les applications de la norme avionique DO-178C niveau A, où la couverture de code au niveau du code d'assemblage s'ajoute à l'instruction, à la branche et au MC/DC. Heureusement pour nos clients, Parasoft automatise la couverture du code assembleur, également connue sous le nom de vérification du code objet, dans le cadre de notre offre de solutions.
Couverture de l'état
La couverture des instructions répond si chaque instruction de l'application logicielle a été exécutée. Une instruction est une unité syntaxique unique du langage de programmation qui exprime une action à effectuer.
Voici un exemple d'instruction simple : int* ptr = ptr + 5;
Couverture des conditions
La couverture des conditions répond à la question : chaque sous-expression booléenne a-t-elle été évaluée à la fois comme vraie et fausse ? Les conditions sont évaluées comme vraies ou fausses en fonction des opérateurs de relation tels que ==, !=, <, > et autres. Différents chemins d'exécution sont effectués en fonction du résultat évalué. Ainsi, pour la couverture d’une condition telle que (A > 7), vous aurez besoin de deux cas de test. Un cas de test où A est égal à 0, qui satisfait un vrai résultat, et un cas de test où A est égal à, disons, 9 satisfaisant un faux résultat.
Couverture des décisions
La couverture des décisions répond à la question : chaque sous-expression non booléenne a-t-elle été évaluée à la fois comme vraie et fausse ? Les décisions sont des expressions composées de conditions et d'un ou plusieurs opérateurs logiques && ou ||. Pour obtenir une couverture de décision pour une décision telle que ((A>7) && (B<=0)), vous avez besoin de cas de test qui démontrent un résultat vrai et faux pour chaque décision.
- Un cas de test où A est supérieur à 7 et B est inférieur ou égal à 0 satisfait un vrai résultat.
- Un cas de test où A est inférieur à 7 ou B est supérieur à 0 satisfait un résultat faux.
Il est important de noter que la durée de couverture des décisions a été surchargée. Pour certains secteurs, la couverture des décisions signifie la couverture des succursales.
Couverture de la succursale
La couverture des branches répond à la question : chaque « chemin » dans une structure de contrôle de conditions et de décisions (if, switch, while catch, etc.) a-t-il été exécuté ? Dans certaines constructions de code complexes, la couverture des branches est insuffisante, c'est pourquoi une couverture de décision de condition modifiée est recommandée en plus de la couverture des branches.
Couverture de décision relative aux conditions modifiées (MC/DC)
MC/DC répond à la question : toutes les conditions contenues dans les décisions ont-elles été évaluées en fonction de tous les résultats possibles au moins une fois ? Il s'agit d'une combinaison de couverture de branches, de conditions et de décisions, mais beaucoup plus solide. Il garantit que :
- Chaque instruction de contrôle prend tous les résultats possibles au moins une fois.
- Chaque condition prend tous les résultats possibles au moins une fois.
- Il a été démontré que chaque condition d’une décision affecte indépendamment le résultat de cette décision.
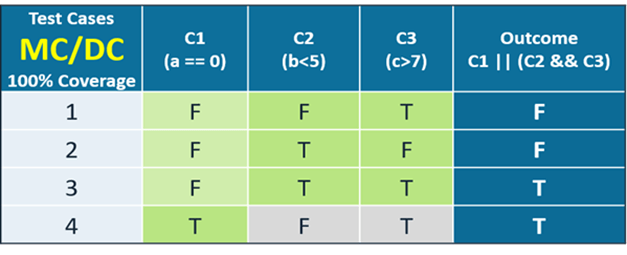
Si vous prenez l'énoncé de décision de condition (C1 || (C2 && C3)) indiqué dans le tableau, il a :
- Trois conditions : C1, C2 et C3
- Deux décisions : le OU (||) et le ET (&&)
Sur la base des exigences MC/DC, si la condition 1 est fausse et parce que la décision est une OU, vous devez évaluer les conditions 2 et 3 pour déterminer l'effet sur le résultat.
Cependant, si la condition 1 est vraie, alors le résultat est automatiquement vrai et vous n'avez pas besoin d'évaluer les conditions 2 et 3.
Il existe une formule pour MC/DC pour déterminer le nombre minimum de cas de test requis pour satisfaire une couverture MC/DC à 100 %. C'est le nombre de conditions plus 1. Le tableau l'illustre clairement.
Autres types de couverture
D’autres types de couverture répondent aux questions suivantes.
- Couverture fonctionnelle. Chaque instruction d’une fonction de l’application a-t-elle été exécutée ?
- Couverture des appels. Chaque fonction du programme a-t-elle été appelée ?
- Couverture de ligne. Chaque ligne du programme a-t-elle été exécutée ?
- Couverture des bords. Chaque branche du programme a-t-elle été exécutée ?
- Couverture du chemin. Tous les itinéraires possibles à travers une partie donnée du code ont-ils été exécutés ?
- Couverture entrée/sortie. Tous les appels et retours possibles de la fonction ont-ils été exécutés ?
- Couverture en boucle. Chaque boucle possible a-t-elle été exécutée zéro fois, une fois et plusieurs fois ?
- Bloquer la couverture. Chaque groupe d'instructions du début à la fin ou if-else, case, wait, while ou for de la boucle, etc. a-t-il été exécuté ?
Comment mesurer la couverture du code ?
Puisqu’il existe différents types de structure de couverture de code, il existe des métriques de couverture de code pour chacun. Si votre objectif ou exigence est une couverture à 100 % des relevés, des succursales et des MC/DC, vous devez remplir une couverture à 100 % des relevés, des succursales à 100 % et des couvertures MC/DC à 100 %.
Il existe également des constructions de codage dans lesquelles les cas de test ne peuvent pas être créés pour atteindre une ligne de code particulière. Par exemple, une instruction return suit une boucle infinie. Pour les applications critiques pour la sécurité où une couverture des instructions à 100 % est obligatoire, les utilisateurs peuvent mesurer et prendre en compte cette ligne de code en la parcourant dans un débogueur. Cette inspection visuelle est acceptable et valable comme approche pour mesurer la couverture du code. Pour faciliter les efforts nécessaires à la collecte de la couverture du code, il est important de sélectionner la meilleure solution disponible. Parasoft est cette solution.
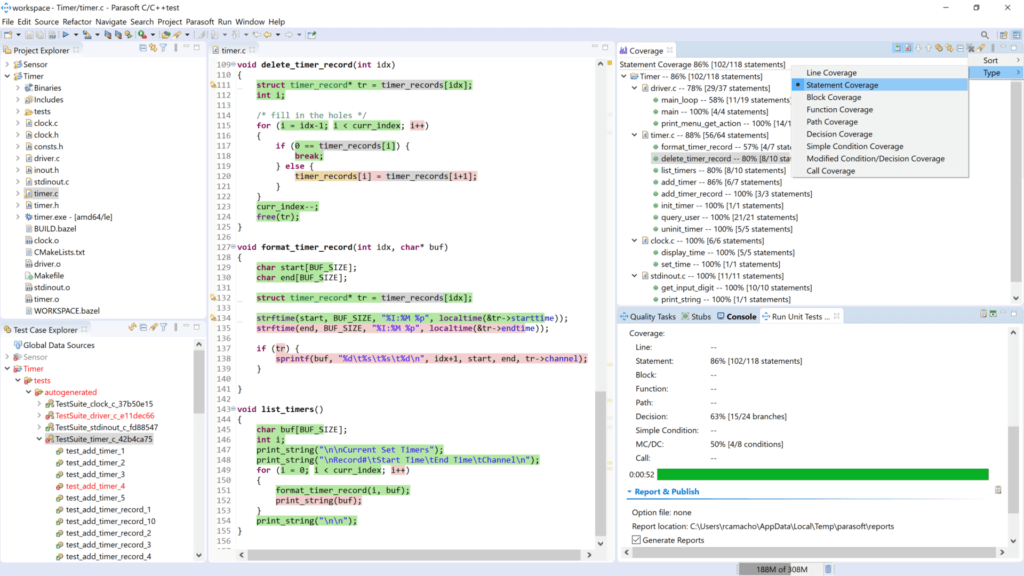
Étape 1. Choisissez un outil de couverture de code
Comme mentionné, la couverture du code est collectée grâce à l'utilisation de diverses méthodes de test telles que les tests manuels, les tests unitaires, les tests système, etc. En outre, le code est instrumenté pour détecter l'exécution du code et collecter divers types de couverture de code structurel tels que les instructions, les branches et MC/DC.
En outre, pour les systèmes critiques pour la sécurité, certaines parties prenantes exigent d'effectuer une couverture de code sur le matériel cible réel et de certifier l'outil de couverture pour une utilisation sur des systèmes critiques pour la sécurité. Par conséquent, choisir un outil de couverture de code est une étape extrêmement importante à franchir car elle ouvre la voie à un voyage fluide et productif.
Étape 2. Intégrer l'outil
Les solutions de couverture de code de Parasoft s'intègrent de manière transparente dans les IDE comme Eclipse, MSVS, VS Code et de nombreux autres éditeurs, ce qui rend leur utilisation et leur déploiement intuitifs. Les organisations peuvent également choisir d'instrumenter leur application et d'exécuter leurs tests existants. En outre, un rapport de couverture est généré.
La plupart des clients intègrent la solution de couverture de code de Parasoft dans leur pipeline d'intégration continue (CI). Dans le cadre du processus de construction, le code est instrumenté. Pendant la phase de test DevOps, la couverture du code est capturée. Pour les applications critiques en matière de sécurité, la couverture du code peut également être capturée lors de l'exécution du code sur le matériel cible.
Étape 3. Écrire et exécuter des tests
Outils de développement et de test Parasoft comme Test C / C ++ et Jtest automatisez la création de scénarios de test pour les tests unitaires, les tests d'intégration et les tests système. Des fonctionnalités telles que la création automatisée de scénarios de tests unitaires peuvent générer jusqu'à 80 % de couverture de code ou plus à partir de l'exécution des scénarios de tests créés automatiquement.
Les scénarios de test générés automatiquement sont également des scénarios de test intelligents, ce qui signifie que le code est analysé et que les scénarios de test sont créés pour exposer des défauts réels, tels que des conditions hors limites, des pointeurs nuls, des débordements de tampon, une division par zéro, etc. Cette solution d'une simple pression sur un bouton permet d'énormes économies de main d'œuvre et une augmentation incroyable de la productivité. Les éditeurs d'interface graphique et la fonction d'assistant avec des conseils étape par étape facilitent la création de cas de test.
Étape 4. Générer un rapport de couverture
Les rapports de couverture du code Parasoft sont exceptionnels. Avec des lignes en surbrillance et codées par couleur visibles dans votre IDE ou éditeur de code préféré, DTP génère des fichiers de code en couleur pour détecter visuellement les lignes de code qui n'ont pas été testées et mises à disposition à des fins d'audit. Le plus convaincant est Solution d'analyse et de reporting de tableaux de bord Web PAO de Parasoft. Il affiche des graphiques de couverture de code en cours, les zones à risque et des widgets ciblés sur la couverture des déclarations, la couverture des succursales, etc. Il s’agit exactement des données complètes dont la direction a besoin pour suivre les progrès au-delà de la couverture du code. Il montre également la santé du projet et la qualité du code dans son ensemble.
Étape 5. Examiner et améliorer
Étant donné que nos solutions de couverture de code et de tests logiciels sont spécialement conçues pour s'intégrer à votre flux de travail CI/CD, les équipes peuvent examiner leurs progrès à chaque réunion de revue de sprint, s'adapter aux changements d'exigences et améliorer les processus qui améliorent la productivité et la qualité du code. Les solutions Parasoft sont conçues pour prendre en charge les méthodologies Agile modernes. C'est pourquoi Parasoft s'intègre à GitHub, GitLab, Azure DevOps, Bazel, Jira, Jenkins, Bamboo, etc.
Les deux grands pièges de la couverture du code
La mesure de la couverture du code fait partie de ces choses qui attirent toujours mon attention. D’une part, je trouve souvent que les organisations ne savent pas forcément quelle quantité de code elles couvrent lors des tests, ce qui est surprenant ! À l’autre extrémité du spectre de couverture, il existe des organisations pour lesquelles le nombre est si important que la qualité et l’efficacité des tests n’ont plus d’importance.
La couverture du code peut être un chiffre intéressant pour évaluer la qualité de votre logiciel, mais il est important de se rappeler qu'il s'agit d'un moyen plutôt que d'une fin. Nous ne voulons pas de couverture pour le plaisir de la couverture. Nous voulons une couverture parce qu'elle est censée indiquer que nous avons fait du bon travail en testant le logiciel. Si les tests eux-mêmes ne sont pas significatifs, en avoir davantage n’indique certainement pas un meilleur logiciel. L’objectif important est de s’assurer que chaque morceau de code est testé et pas seulement exécuté.
Cela signifie que même si une faible couverture signifie que nous ne testons probablement pas suffisamment, une couverture élevée ne signifie pas nécessairement en soi une qualité élevée. La situation est plus compliquée que cela.
Piège n° 1 : « Nous ne connaissons pas notre couverture »
Ne pas connaître votre couverture me semble déraisonnable. Les outils de couverture sont bon marché et nombreux. Un véritable problème auquel les équipes sont confrontées lorsqu’elles tentent de mesurer la couverture est que le système est trop compliqué. Lorsque vous créez une application à partir d'éléments superposés, le simple fait de savoir où placer les compteurs de couverture peut s'avérer une tâche ardue. Je suggérerais que s'il est difficile de mesurer la couverture dans votre application, vous devriez réfléchir à deux fois à l'architecture.
Une deuxième façon de tomber dans ce piège se produit avec les organisations qui peuvent effectuer de nombreux tests, mais sans véritable numéro de couverture, car elles ne disposent pas d'un outil ou d'une solution de couverture de code capable de regrouper les chiffres de différentes exécutions de tests. Si vous effectuez des tests manuels, des tests fonctionnels, des tests unitaires et d'autres types, assurez-vous que l'outil que vous utilisez peut regrouper correctement la couverture de toutes vos méthodes de test.
Chez Parasoft, nous exploitons la grande quantité de données granulaires capturées avec l'outil de rapports et d'analyse Parasoft DTP, qui fournit une vue complète et agrégée de la couverture du code en contexte. Les moniteurs d'application collectent des données de couverture directement à partir de l'application pendant son test, puis envoient ces informations à DTP, qui regroupe les données de couverture de toutes les pratiques de test, équipes de test et exécutions de tests.
Si cela vous semble être une quantité d’informations assez importante, vous avez raison ! DTP fournit un tableau de bord interactif pour vous aider à parcourir les données et à prendre des décisions sur où concentrer les efforts de test. Voir l'exemple de tableau de bord ci-dessous.
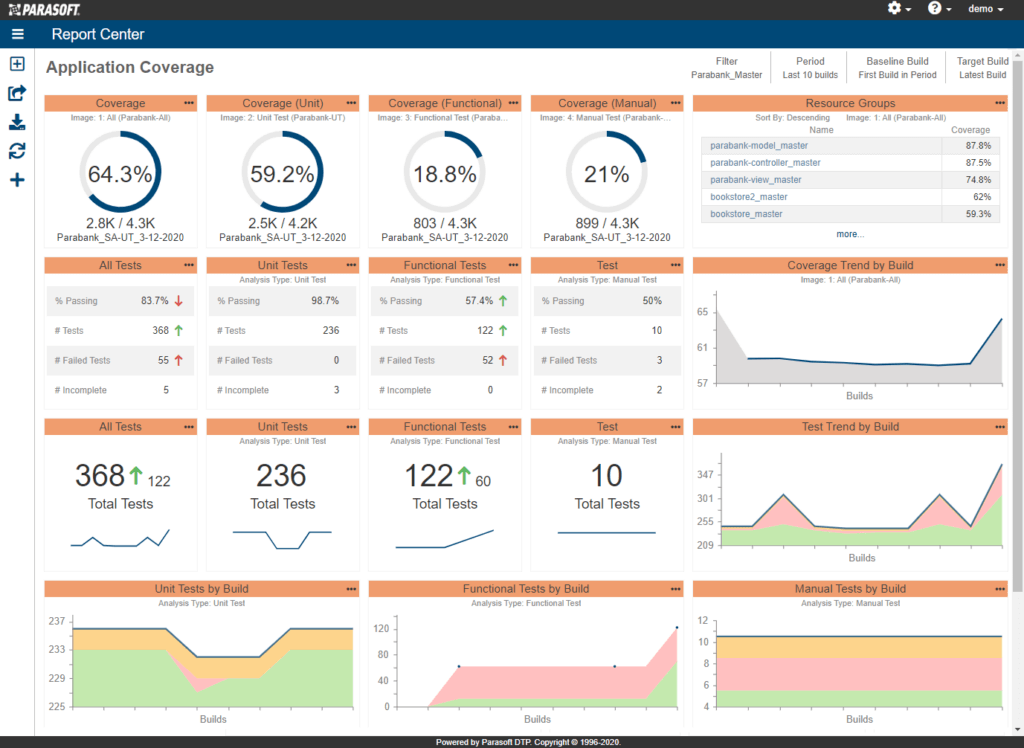
Si plusieurs tests ont couvert le même code, il ne sera pas surestimé. Les parties non testées du code sont rapides et faciles à voir. Cela vous montre quelles parties de l'application ont été bien testées et lesquelles ne l'ont pas été.
Donc, plus d'excuses pour ne pas mesurer la couverture.
Piège n° 2 : « La couverture, c'est tout ! »
Il est courant de penser à tort que la couverture est essentielle. Une fois que les équipes peuvent mesurer la couverture, il n'est pas rare que les managers disent : « Augmentons ce chiffre ». Finalement, le nombre lui-même devient plus important que les tests. La meilleure analogie est peut-être celle du fondateur de Parasoft, Adam Kolawa :
«C'est comme demander à un pianiste de couvrir 100% des touches du piano plutôt que d'appuyer uniquement sur les touches qui ont du sens dans le contexte d'un morceau de musique donné. Quand il joue le morceau, il obtient le niveau de couverture clé qui lui convient. »
C’est là que réside le problème. Une couverture insensée est la même chose qu'une musique insensée. La couverture doit refléter une utilisation réelle et significative du code.
Dans certains secteurs, comme ceux critiques pour la sécurité, par exemple, la mesure de couverture à 100 % est une exigence. Mais même dans ce cas, il est trop facile de considérer toute exécution d’une ligne de code comme un test significatif, ce qui peut ne pas être vrai. Pour déterminer si un test est un bon test, posez les deux questions de base suivantes.
- Qu'est-ce que cela signifie lorsque le test échoue?
- Qu'est-ce que cela signifie lorsque le test réussit?
Si vous ne parvenez pas à répondre à l’une de ces questions, vous avez probablement un problème avec votre test. Si vous ne pouvez répondre à aucune de ces questions, le test pose probablement plus de problèmes qu'il n'en vaut la peine. Pour sortir de ce piège, il faut d’abord comprendre que le véritable objectif est de créer des tests utiles et significatifs. La couverture est importante. Améliorer la couverture est un objectif louable.
Aperçu final : la couverture du code comme chemin vers l'excellence en matière de tests
Bien que la couverture du code soit une mesure précieuse qui peut aider à identifier les parties de code non testées et à améliorer la qualité globale d'une base de code, elle doit être considérée comme un aspect d'une stratégie de test plus large. Même atteindre une couverture de code à 100 % ne signifie pas nécessairement l’absence de bugs ni ne garantit l’exactitude du logiciel. Cela ne garantit pas à lui seul l’excellence des tests.
Il s’agit de l’une des nombreuses pratiques qui contribuent à une approche de test complète. La couverture du code peut faire partie des efforts d'assurance qualité, mais d'autres aspects des tests, tels que les tests unitaires, les tests d'intégration, les tests système et les tests d'acceptation utilisateur, sont tout aussi importants. L'excellence des tests implique une combinaison de différents types de tests, une bonne conception des tests, des cas de tests significatifs, ainsi qu'une évaluation et une amélioration continues du processus de test.



