
Rejoignez-nous le 30 avril : dévoilement de Parasoft C/C++test CT pour l'excellence en matière de tests continus et de conformité | En savoir plus
Aller à la section
Comment éviter le débordement de tampon et autres bogues de gestion de la mémoire

28 novembre 2023
10 min lire
Lorsque le volume de données dépasse la capacité de stockage de la mémoire tampon, vous subissez un débordement de tampon. Découvrez comment la fonctionnalité de vérificateur d'analyse statique de la solution Parasoft C/C++ peut vous aider à gérer les erreurs dues aux dépassements de mémoire tampon.
Aller à la section
Aller à la section
La gestion de la mémoire est pleine de dangers, notamment en C et C++. En fait, les bogues associés aux faiblesses de la gestion de la mémoire constituent une part importante du Top 25 CWE. Huit des 25 premiers sont directement liés à débordements de tampon, de mauvais pointeurs et une gestion de la mémoire.
La principale faiblesse logicielle est de loin CWE-119, "Improper Restriction of Operations within the Bounds of a Memory Buffer". Ces types d'erreurs figurent en bonne place dans les problèmes de sûreté et de sécurité dans toutes sortes de logiciels, y compris les applications critiques pour la sécurité dans les automobiles, les dispositifs médicaux et l'avionique.
Voici les erreurs de mémoire liées aux énumérations de faiblesses courantes du CWE Top 25:
| Rang | ID | Nom |
|---|---|---|
| CWE-787 | Écriture hors limites | |
| CWE-416 | Utiliser après gratuit | |
| CWE-125 | Hors limites Lire | |
| CWE-476 | Déréférence de pointeur NULL | |
| CWE-190 | Débordement d'entiers ou enveloppement | |
| CWE-119 | Restriction inappropriée des opérations dans les limites d'un tampon mémoire |
Bien que ces erreurs affectent le C, le C ++ et d'autres langages depuis des décennies, elles se produisent toujours avec un nombre croissant de nos jours. Ce sont des bogues dangereux en termes de conséquences sur la qualité, la sécurité et la fiabilité, et leur présence est l'une des principales causes de vulnérabilités de sécurité.
Que sont les débordements de tampon ?
Un débordement de tampon se produit lorsque plus de données sont écrites dans un morceau de mémoire, ou dans un tampon, qu'il ne peut en contenir, par exemple, si vous essayez de mettre 12 lettres dans une case qui n'en contient que 10. Cela peut conduire à l'écrasement de la mémoire adjacente. espaces, provoquant un comportement imprévisible dans un programme.
Les erreurs de dépassement de tampon peuvent avoir un impact significatif sur la qualité, la sécurité et la fiabilité des logiciels. Du point de vue de la sécurité, les acteurs malveillants peuvent exploiter les erreurs de dépassement de tampon pour exécuter du code arbitraire ou perturber les opérations d'un système. En effet, lorsqu'un débordement de tampon se produit, un attaquant peut être en mesure de contrôler quelles données sont écrites au-delà du tampon, ce qui lui permet potentiellement de modifier le flux d'exécution du programme.
Par conséquent, il est crucial que les développeurs mettent en œuvre une gestion robuste des données et testent correctement leurs logiciels pour éviter débordement de tampon erreurs et maintenir l’intégrité et la sécurité de leurs logiciels.
Principale cause de vulnérabilités de sécurité
Microsoft découvert qu'au cours des 12 dernières années, plus de 70 % des vulnérabilités de sécurité de leurs produits étaient dues à problèmes de sécurité de la mémoire. Ces types de bugs constituent la plus grande surface d’attaque pour leur application et les pirates informatiques l’utilisent. Selon leurs recherches, les principales causes des attaques de sécurité étaient l'utilisation hors limites, l'utilisation après libération et l'utilisation non initialisée. Comme ils le soulignent, les classes de vulnérabilité existent depuis 20 ans ou plus et sont toujours répandues aujourd'hui.
De la même manière, Google a constaté que 70 % des failles de sécurité du projet Chromium, la base open source du navigateur Chrome, sont dues à ces mêmes problèmes de gestion de la mémoire. Leur principale cause était également l'utilisation après libération, les autres gestions de mémoire non sécurisées arrivant en deuxième position.
Compte tenu de ces exemples de découvertes du monde réel, il est essentiel que les équipes logicielles prennent ces types d'erreurs au sérieux. Heureusement, il existe des moyens de prévenir et de détecter ces types de problèmes grâce à une analyse statique efficace et efficiente.
Comment les erreurs de gestion de la mémoire se transforment en vulnérabilités de sécurité
Dans la plupart des cas, les erreurs de gestion de la mémoire sont le résultat de mauvaises pratiques de programmation avec l'utilisation de pointeurs en C / C ++ et l'accès direct à la mémoire. Dans d'autres cas, cela est lié à de mauvaises hypothèses sur la longueur et le contenu des données.
Ces faiblesses logicielles sont le plus souvent exploitées avec des données corrompues, des données extérieures à l'application dont la longueur ou le format n'ont pas été vérifiés. L'infâme Heartbleed la vulnérabilité est un cas d'exploitation d'un débordement de tampon. Techniquement, c'est une surcharge de tampon. Comme nous en avons discuté dans notre blog précédent sur Injections SQL, l'utilisation d'entrées non contrôlées et sans contrainte est un risque pour la sécurité.
Examinons certaines des principales catégories de faiblesses des logiciels de gestion de la mémoire. Le plus important est CWE-119: Restriction incorrecte des opérations dans les limites d'un tampon mémoire.
Débordement de tampon
Langages de programmation, le plus souvent C et C++, qui permettent un accès direct à la mémoire et ne vérifient pas automatiquement que les emplacements accédés sont valides et sujets à erreurs de corruption de mémoire. Cette corruption peut se produire dans les zones de données et de code de la mémoire, ce qui peut exposer des informations sensibles, conduire à une exécution involontaire de code ou provoquer le blocage d'une application.
L'exemple suivant montre un cas classique de dépassement de tampon de CWE-120:
char last_name[20];
printf ("Enter your last name: ");
scanf ("%s", last_name);Dans ce cas, il n'y a aucune restriction sur l'entrée de l'utilisateur depuis scanf () mais la limite de la longueur de nom de famille est de 20 caractères. La saisie d'un nom de famille de plus de 20 caractères finit par copier l'entrée utilisateur en mémoire au-delà des limites de la mémoire tampon nom de famille. Voici un exemple plus subtil de CWE-119:
void host_lookup(char *user_supplied_addr){
struct hostent *hp;
in_addr_t *addr;
char hostname[64];
in_addr_t inet_addr(const char *cp);
/*routine that ensures user_supplied_addr is in the right format for conversion */
validate_addr_form(user_supplied_addr);
addr = inet_addr(user_supplied_addr);
hp = gethostbyaddr( addr, sizeof(struct in_addr), AF_INET);
strcpy(hostname, hp->h_name);
}Cette fonction prend une chaîne fournie par l'utilisateur contenant une adresse IP, par exemple 127.0.0.1, et récupère le nom d'hôte correspondant.
La fonction valide l'entrée utilisateur (bien!) Mais ne vérifie pas la sortie de gethostbyaddr () (mauvais !) Dans ce cas, un nom d'hôte long suffit à faire déborder le tampon du nom d'hôte qui est actuellement limité à 64 caractères. Notez que si gethostaddr () renvoie un null lorsqu'un nom d'hôte est introuvable, il y a aussi une erreur de déréférence de pointeur nul!
Erreurs d'utilisation après utilisation gratuite
Il est intéressant de noter que Microsoft, dans son étude, a observé que les erreurs d'utilisation après libération étaient les problèmes de gestion de la mémoire les plus courants auxquels ils étaient confrontés. Comme son nom l'indique, l'erreur concerne l'utilisation de pointeurs dans le cas du C/C++ qui accèdent à la mémoire précédemment libérée. C et C++ s'appuient généralement sur le développeur pour gérer l'allocation de mémoire, ce qui peut souvent être difficile à réaliser correctement. Comme le montre l’exemple suivant tiré de CWE-416, il est souvent facile de supposer qu’un pointeur est toujours valide :
char* ptr = (char*)malloc (SIZE);
if (err) {
abrt = 1;
free(ptr);
}
...
if (abrt) {
logError("operation aborted before commit", ptr);
}Dans l'exemple ci-dessus, le pointeur ptr est libre si une erreur est vraie, mais est ensuite déréférencé plus tard, après avoir été libéré, si abré est vrai, ce qui est défini sur vrai si se tromper est vrai. Cela peut sembler artificiel, mais s'il y a beaucoup de code entre ces deux extraits de code, il est facile de l'oublier. De plus, cela peut se produire uniquement dans une condition d’erreur qui n’est pas correctement testée.
Déréférence de pointeur NULL
Une autre faiblesse logicielle courante consiste à utiliser des pointeurs ou des objets en C++ et Java qui sont censés être valides mais qui sont NULL. Bien que ces déréférencements soient considérés comme des exceptions dans des langages comme Java, ils peuvent provoquer l’arrêt, la fermeture ou le crash d’une application. Prenons l'exemple suivant, en Java, de CWE-476:
String cmd = System.getProperty("cmd");
cmd = cmd.trim();Cela semble anodin car le développeur peut supposer que le getProperty () La méthode renvoie toujours quelque chose. En fait, si la propriété "Cmd" n'existe pas, un NULL est renvoyé provoquant une exception de déréférencement NULL lorsqu'il est utilisé. Bien que cela semble anodin, cela peut conduire à résultats désastreux.
Dans de rares cas, lorsque NULL est équivalent à l'adresse mémoire 0x0 et qu'un code privilégié peut y accéder, l'écriture ou la lecture de la mémoire est possible, ce qui peut conduire à l'exécution de code.
Stratégies d'atténuation efficaces
Il existe plusieurs mesures d'atténuation que les développeurs devraient implémenter. Principalement, les développeurs doivent s'assurer que les pointeurs sont valides pour des langages comme C et C ++ avec une logique vérifiée et une vérification approfondie.
Pour tous les langages, il est impératif que tout code ou bibliothèque qui manipule la mémoire valide les paramètres d'entrée pour empêcher l'accès hors limites. Voici quelques options d'atténuation disponibles. Mais les développeurs ne devraient pas compter sur eux pour compenser les mauvaises pratiques de programmation.
Choix du langage de programmation
Certains langages offrent une protection intégrée contre les débordements tels que Ada et C #.
Utilisation de bibliothèques sûres
L'utilisation de bibliothèques, comme la bibliothèque de chaînes Safe C, qui fournissent des vérifications intégrées pour éviter les erreurs de mémoire, est disponible. Cependant, tous les débordements de tampon ne sont pas le résultat d'une manipulation de chaîne. Sauf cela, les programmeurs doivent toujours recourir à des fonctions qui prennent la longueur des tampons comme arguments, par exemple, strncpy () versus strcpy ().
Compilation et durcissement du temps d'exécution
Cette approche utilise des options de compilation qui ajoutent du code à l'application pour surveiller les utilisations des pointeurs. Ce code ajouté peut empêcher les erreurs de débordement de se produire au moment de l'exécution.
Durcissement de l'environnement d'exécution
Les systèmes d'exploitation ont des options pour empêcher l'exécution de code dans les zones de données d'une application, comme un débordement de pile avec injection de code. Il existe également des options pour organiser aléatoirement le mappage de la mémoire afin d'empêcher les pirates de prédire où le code exploitable peut résider.
Malgré ces mesures d'atténuation, rien ne remplace les pratiques de codage appropriées pour éviter les débordements de tampon en premier lieu. Par conséquent, la détection et la prévention sont essentielles pour réduire les risques de ces faiblesses logicielles.
Décaler la détection et l'élimination des débordements de tampon
Adopter une approche DevSecOps pour le développement de logiciels signifie intégrer la sécurité dans tous les aspects du pipeline DevOps. Tout comme les processus de qualité comme l'analyse de code et les tests unitaires sont poussés le plus tôt possible dans SDLC, il en va de même pour la sécurité.
Les débordements de mémoire tampon et autres erreurs de gestion de la mémoire pourraient appartenir au passé si les équipes de développement adoptaient une telle approche plus largement. Comme le montrent les recherches de Google et Microsoft, ces erreurs représentent toujours 70% de leurs failles de sécurité. Quoi qu'il en soit, décrivons une approche qui les empêche le plus tôt possible.
La recherche et la correction des erreurs de gestion de la mémoire sont payantes par rapport à l'application de correctifs à une application publiée. L'approche de détection et de prévention décrite ci-dessous est basée sur le déplacement vers la gauche de l'atténuation des débordements de zones tampons vers les premiers stades de développement. Et en renforçant cela avec la détection via l'analyse de code statique.
Détection
La détection des erreurs de gestion de la mémoire repose sur une analyse statique pour trouver ces types de vulnérabilités dans le code source. La détection se produit sur le bureau du développeur et dans le système de construction. Il peut inclure du code existant, hérité et tiers.
La détection continue des problèmes de sécurité garantit la détection de tous les problèmes qui:
- Les développeurs ont raté l'IDE.
- Existe dans un code antérieur à votre nouvelle approche de détection et de prévention.
L'approche recommandée est un modèle de confiance mais de vérification. L'analyse de sécurité est effectuée au niveau de l'EDI où les développeurs prennent des décisions en temps réel en fonction des rapports qu'ils reçoivent. Ensuite, vérifiez au niveau de la construction. Idéalement, l'objectif au niveau de la construction n'est pas de trouver des vulnérabilités. C'est pour vérifier que le système est propre.
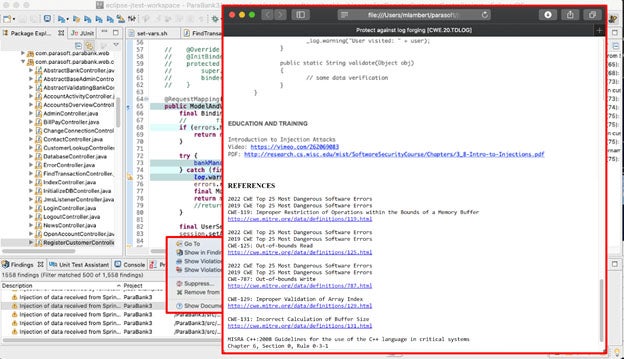
Parasoft C / C ++test inclut vérificateurs d'analyse statique pour ces types d'erreurs de gestion de la mémoire, y compris les dépassements de mémoire tampon. Prenons l'exemple suivant tiré du test C / C ++.
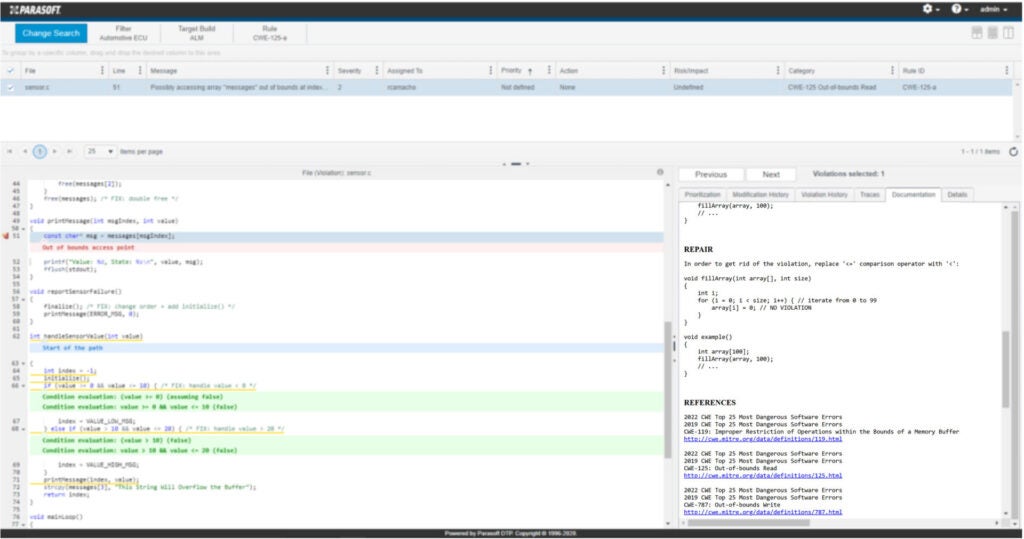
Zoom sur les détails, la fonction printMessage () l'erreur détecte l'erreur:
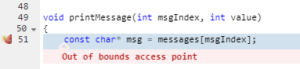
Le test Parasoft C / C ++ fournit également des informations de trace sur la manière dont l'outil est arrivé à cet avertissement:
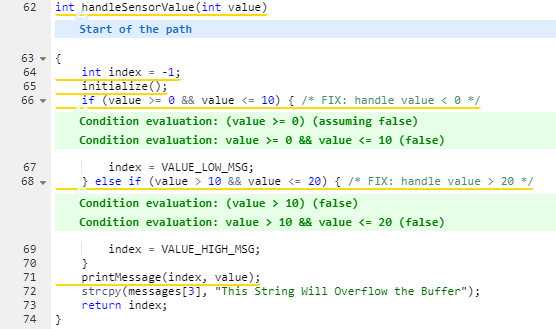
La barre latérale affiche des détails sur la façon de réparer cette vulnérabilité ainsi que les références appropriées:
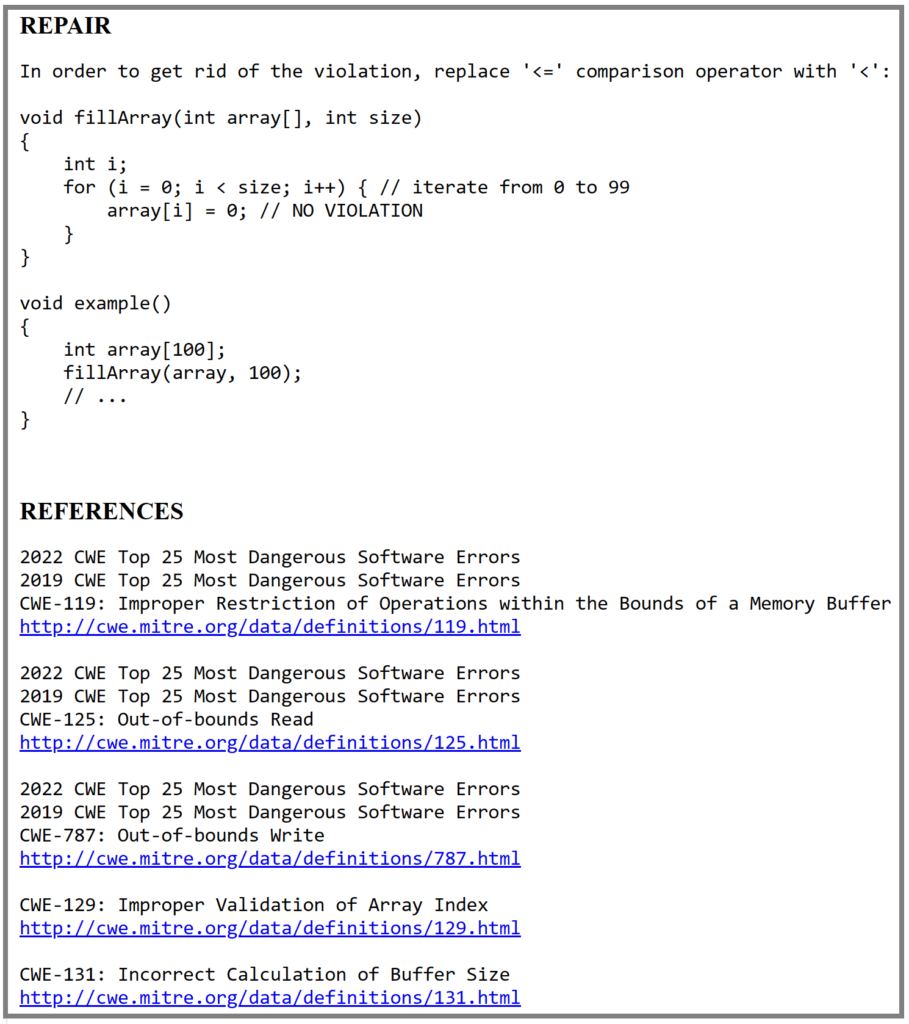
Une détection précise ainsi que des informations complémentaires et des recommandations de correction sont essentielles pour rendre l'analyse statique et la détection précoce de ces vulnérabilités utiles et immédiatement exploitables pour les développeurs.
Prévention des débordements de mémoire tampon et autres erreurs de gestion de la mémoire
Le moment et le lieu idéaux pour éviter les débordements de tampon est lorsque les développeurs écrivent du code dans leur IDE. Les équipes qui adoptent des normes de codage sécurisé telles que SEI CERT C pour C et C ++ et OWASP Top 10 pour Java et .NET ou CWE Top 25, ont toutes des directives qui avertissent des erreurs de gestion de la mémoire.
Par exemple, CERT C inclut les règles suivantes pour la gestion de la mémoire :

Ces règles incluent des techniques de codage préventives qui évitent en premier lieu les erreurs de gestion de la mémoire. Chaque ensemble de règles comprend une évaluation des risques ainsi que les coûts de remédiation, permettant aux équipes logicielles de hiérarchiser les directives comme suit :
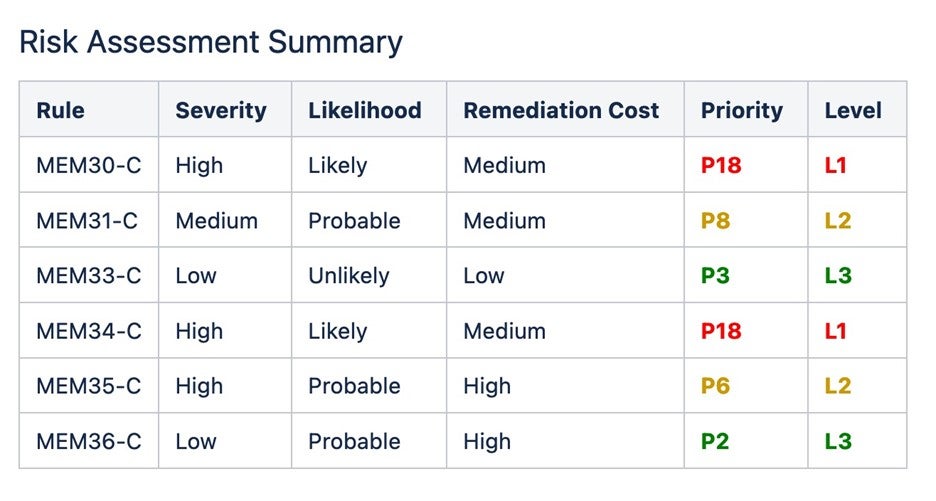
Dans l'usage du mot règle par le CERT C, la violation d'une règle est la plus susceptible de provoquer un défaut, et la conformité doit être effectuée automatiquement ou manuellement par l'inspection du code. Les règles sont considérées comme obligatoires. Toute exception faite en cas de violation des règles doit être documentée.
D’un autre côté, une recommandation fournit des orientations qui, lorsqu’elles sont suivies, devraient améliorer la sûreté, la fiabilité et la sécurité. Toutefois, une violation d’une recommandation n’indique pas nécessairement la présence d’un défaut dans le code. Les recommandations ne sont pas obligatoires.
CERT C propose les recommandations suivantes pour la gestion de la mémoire :

L’évaluation des risques associés est la suivante pour ces recommandations :
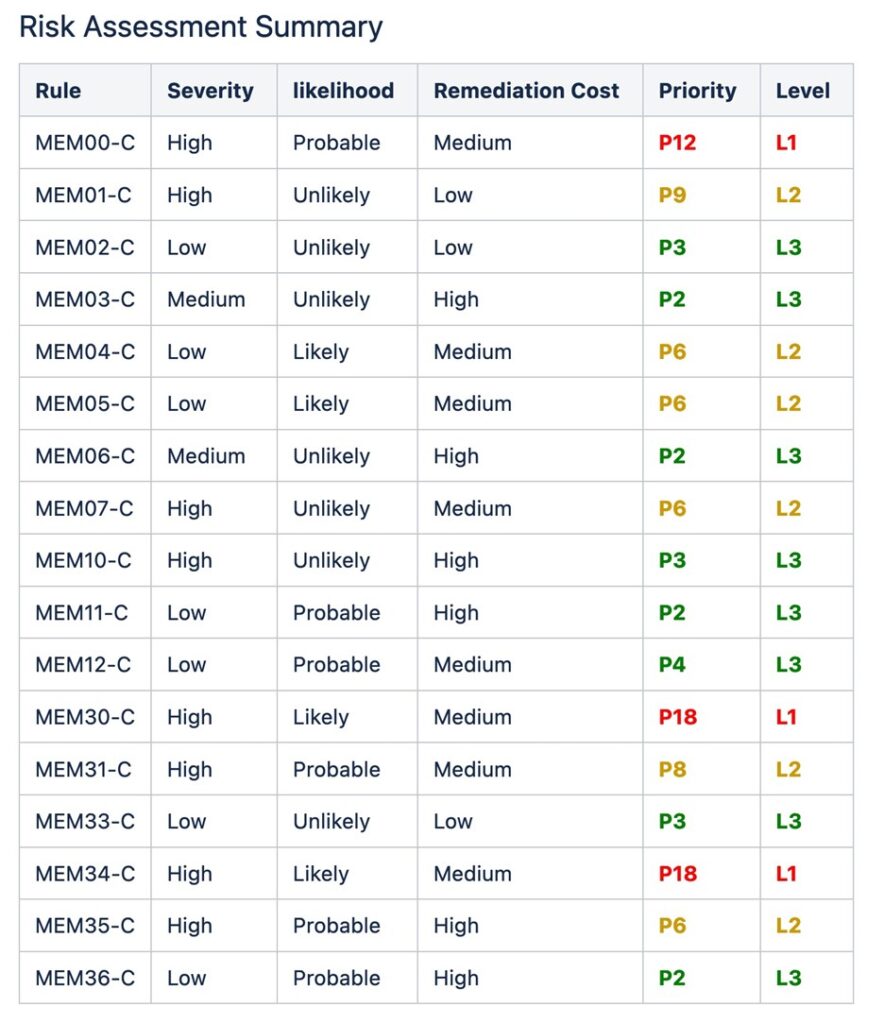
Une stratégie de prévention clé consiste à adopter une norme de codage adaptée des directives de l'industrie comme SEI CERT et à l'appliquer dans le codage futur. La prévention de ces vulnérabilités grâce à de meilleures pratiques de codage est moins coûteuse, moins risquée et offre le retour sur investissement le plus élevé.
L'exécution d'une analyse statique du code nouvellement créé est simple et rapide. Il est facile pour les équipes d'intégrer à la fois sur l'EDI de bureau et dans le processus CI / CD. Pour éviter que ce code ne soit intégré à la construction, il est recommandé d'étudier les avertissements de sécurité et les pratiques de codage non sécurisées à ce stade.
Un élément tout aussi important pour détecter les mauvaises pratiques de codage est l’utilité des rapports. Il est important de comprendre la cause première des violations de l’analyse statique pour les corriger rapidement et efficacement. C'est là que des outils commerciaux tels que Parasoft Test C / C ++, pointTESTet Jtest éclat.
Les outils de test automatisés de Parasoft donnent des traces complètes des avertissements, les illustrent dans l'EDI et collectent en permanence des informations de construction et d'autres informations. Ces données collectées ainsi que les résultats des tests et les mesures fournissent une vue complète de la conformité avec la norme de codage de l'équipe ainsi que l'état général de la qualité et de la sécurité.
Les développeurs peuvent filtrer davantage les résultats en fonction d'autres informations contextuelles telles que les métadonnées sur le projet, l'âge du code et le développeur ou l'équipe responsable du code. Des outils tels que Parasoft avec intelligence artificielle (IA) et apprentissage automatique (ML) utilisent ces informations pour aider à mieux déterminer les problèmes les plus critiques.
Les tableaux de bord et les rapports incluent les modèles de risque qui font partie des informations fournies par OWASP, CERT et CWE. De cette façon, les développeurs comprennent mieux l'impact des vulnérabilités potentielles signalées par l'outil et lesquelles de ces vulnérabilités à prioriser. Toutes les données générées au niveau IDE sont corrélées avec les activités en aval décrites ci-dessus.
Conclusion : protéger votre code contre les débordements de mémoire tampon
Les débordements de mémoire tampon et autres erreurs de gestion de la mémoire continuent de nuire aux applications. Ils restent une des principales causes de failles de sécurité. Malgré la connaissance de son fonctionnement et de son exploitation, il reste répandu. Voir le Salle de la honte IoT pour des exemples récents.
Nous proposons une approche de prévention et de détection pour compléter les tests de sécurité actifs qui empêchent les débordements de tampon avant qu'ils ne soient écrits dans le code le plus tôt possible dans le SDLC. Prévenir de telles erreurs de gestion de la mémoire au niveau de l'EDI et les détecter dans le pipeline CI/CD est essentiel pour les acheminer hors de votre logiciel.
Les équipes logicielles intelligentes peuvent minimiser les erreurs de gestion de la mémoire. Ils peuvent avoir un impact sur la qualité et la sécurité grâce aux processus, outils et automatisations appropriés dans leurs flux de travail existants.



