
Rejoignez-nous le 30 avril : dévoilement de Parasoft C/C++test CT pour l'excellence en matière de tests continus et de conformité | En savoir plus
Aller à la section
Faciliter la gestion des données de test (TDM) avec la simulation de données
8 août 2021
6 min lire
Vous êtes-vous déjà demandé comment faciliter la gestion des données de test (TDM) avec la simulation de test ? Découvrez comment la solution de données de test virtuelles de Parasoft peut vous aider à y parvenir.
Aller à la section
Aller à la section
Pour permettre des tests d'intégration parallèles qui déplacent les tests fonctionnels à gauche, les organisations peuvent tirer parti de l'approche de Parasoft pour gestion des données de test (TDM) qui utilise l'IA, l'apprentissage automatique et les données de test virtuelles pour remplacer le besoin de points de terminaison physiques et de bases de données. Explorons comment cela fonctionne.
Le problème des données de test
La validation et la vérification des logiciels restent l'un des aspects les plus longs et les plus coûteux du développement de logiciels d'entreprise. L'industrie a accepté que les tests soient difficiles, mais les causes profondes sont souvent négligées. Acquérir, stocker, gérer et utiliser des données de test pour les tests est une tâche difficile qui prend trop de temps.
Nous constatons à partir des données de l'industrie que jusqu'à 60% du temps de développement et de test des applications peut être consacré à des tâches liées aux données, dont une grande partie est la gestion des données de test. Les retards et les dépenses budgétaires ne sont qu'une partie du problème - le manque de données de test entraîne également des tests inadéquats, ce qui est un problème beaucoup plus important, entraînant inévitablement des défauts dans la production.
Webinaire : TDM pour la victoire – Comment la gestion des données de test permet des tests continus
Les solutions traditionnelles du marché pour le TDM n'ont pas réussi à améliorer l'état des défis des données de test - jetons un coup d'œil à certains d'entre eux.
Les 3 approches traditionnelles pour tester la gestion des données
Les approches traditionnelles reposent soit sur la copie d'une base de données de production, soit au contraire sur l'utilisation de données synthétiques générées. Il existe 3 principales approches traditionnelles.
1. Clonez la base de données de production.
Les testeurs peuvent cloner la base de données de production pour avoir quelque chose à tester. Puisqu'il s'agit d'une copie de la base de données de production, l'infrastructure requise doit également être dupliquée. Le respect de la sécurité et de la confidentialité exige que toutes les informations personnelles confidentielles soient étroitement surveillées, si bien que le masquage est souvent utilisé pour masquer ces données.
2. Clonez un sous-ensemble de la base de données de production.
Un sous-ensemble de la base de données de production est un clone partiel de la base de données de production, qui ne comprend que la partie nécessaire aux tests. Cette approche nécessite moins de matériel mais, comme la méthode précédente, nécessite également un masquage des données et une infrastructure similaire à la base de données de production.
3. Générez/synthétisez les données.
En synthétisant les données, on ne s'appuie pas sur les données client, mais les données générées sont encore suffisamment réalistes pour être utiles pour les tests. La synthèse de la complexité d'une base de données de production héritée est une tâche importante, mais elle supprime les défis de sécurité et de confidentialité qui sont présents avec les mécanismes de clonage.
Soyez intelligent : utilisez la simulation pour accélérer les tests d'API
Problèmes avec les approches traditionnelles de la GDT
Tout d'abord, considérons l'approche la plus simple (et étonnamment la plus courante) du TDM d'entreprise, à savoir le clonage d'une base de données de production avec ou sans sous-ensemble. Pourquoi cette approche est-elle si problématique?
- Complexité et coûts de l'infrastructure. Probablement la plus grande chute des approches TDM traditionnelles, les bases de données héritées peuvent résider sur un mainframe ou être constituées de plusieurs bases de données physiques. La duplication d'un seul système de production pour une équipe est une entreprise coûteuse.
- Confidentialité et sécurité des données. La confidentialité et la sécurité sont toujours une préoccupation lors de l'utilisation de bases de données de production, et les environnements de test ne sont souvent pas conformes aux contrôles de confidentialité et de sécurité nécessaires. Le masquage est la solution habituelle pour gérer ces préoccupations, en modifiant les informations sensibles afin de ne révéler aucune information personnellement identifiable, mais malheureusement, le masquage est presque impossible sans risque de fuite d'informations privées car il est possible de désanonymiser les données de test, malgré les meilleurs efforts de la meilleure équipe de test. Les entreprises qui doivent se conformer au RGPD, par exemple, peuvent avoir du mal à convaincre les régulateurs que leur environnement de test cloné répond aux contrôles de confidentialité requis.
- Manque de parallélisme et collisions de données. Compte tenu des coûts d'infrastructure, il existe un ensemble limité de bases de données de test disponibles, et l'exécution de plusieurs tests en parallèle soulève des problèmes de conflits de données. Les tests peuvent supprimer ou modifier des enregistrements sur lesquels d'autres tests s'appuient, par exemple. Ce manque de parallélisme signifie que les tests deviennent moins efficaces et que les testeurs doivent se soucier de l'intégrité des données après chaque session de test.
- Le sous-ensemble n'aide pas beaucoup. Bien qu'il soit possible de créer un sous-ensemble gérable nécessitant moins d'infrastructure, il s'agit d'un processus complexe. L'intégrité référentielle doit être maintenue et les problèmes de confidentialité et de sécurité demeurent dans les sous-ensembles.
- La synthèse des données résout les problèmes de confidentialité, mais nécessite une grande expertise dans les bases de données et le domaine. La création et le remplissage d'une version réaliste d'une base de données de test nécessitent une connaissance approfondie de la base de données existante et la possibilité de recréer une version synthétique avec des données adaptées aux tests. Ainsi, bien que cette approche résout de nombreux problèmes de sécurité et de confidentialité, elle nécessite beaucoup plus de temps de développement pour créer la base de données. Des problèmes d'infrastructure persistent si la base de données de test est volumineuse et le parallélisme peut être limité en fonction du nombre de bases de données de test pouvant être utilisées simultanément.
Résoudre les problèmes de gestion des données de test avec la simulation de données
L'approche simplifiée et plus sûre de gestion des données de test que nous proposons chez Parasoft dans notre SOAtest, Virtualiser, CTP Les outils de données de test virtuel sont beaucoup plus sûrs et résolvent ces problèmes traditionnels. En quoi est-ce différent des approches traditionnelles ?
Testez l'incontestable: Alaska Airlines résout le dilemme de l'environnement de test
La principale différence est qu'il collecte les données de test en capturant le trafic des appels d'API et des transactions JDBC/SQL pendant les tests et l'utilisation normale de l'application. Le masquage est effectué sur les données capturées si nécessaire, et les modèles de données sont générés et affichés dans l'interface de gestion des données de test de Parasoft. Les métadonnées et les contraintes de données du modèle peuvent être déduites et configurées dans l'interface, et des opérations supplémentaires de masquage, de génération et de sous-ensemble peuvent être effectuées. Cela fournit un portail en libre-service où plusieurs ensembles de données jetables peuvent facilement être provisionnés pour donner aux testeurs une flexibilité et un contrôle complets de leurs données de test, comme vous pouvez le voir dans les captures d'écran ci-dessous :
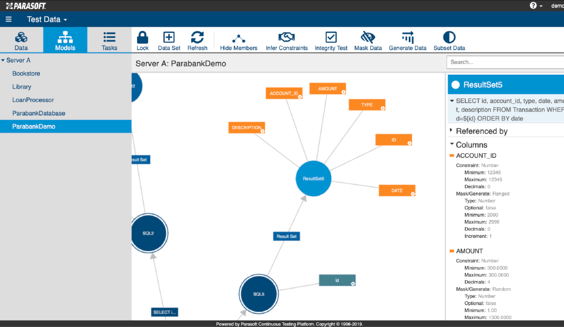
Parasoft's technologie de gestion des données de test virtuel est complétée par la virtualisation des services, où les dépendances back-end contraintes peuvent être simulées pour débloquer les activités de test. Un bon exemple serait de remplacer une dépendance à une base de données physique partagée en la remplaçant par une base de données virtualisée qui simule les transactions JDBC/SQL, permettant des tests parallèles et indépendants qui seraient autrement en conflit. Le moteur de gestion des données de test de Parasoft étend la puissance de la virtualisation des services en permettant aux testeurs de générer, sous-ensemble, masquer et créer des données de test personnalisées individuelles pour leurs besoins.
En remplaçant les dépendances partagées telles que les bases de données, la virtualisation des services supprime le besoin d'infrastructure et la complexité requises pour héberger l'environnement de base de données. À son tour, cela signifie des suites de tests isolées et la capacité de couvrir des cas extrêmes et extrêmes. Bien que les dépendances virtualisées ne soient pas « réelles », les actions avec état, telles que les opérations d'insertion et de mise à jour sur une base de données, peuvent être modélisées dans l'actif virtuel. Voir cela conceptuellement ci-dessous :
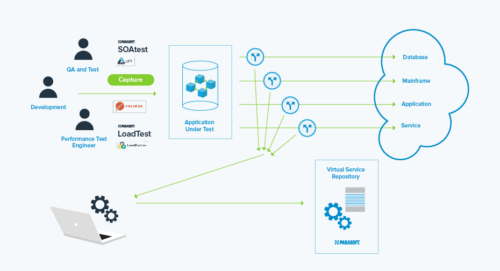
Le principal avantage de cette approche est qu'elle évite les complexités et les coûts d'infrastructure liés au clonage des bases de données, ce qui permet Tests au niveau de l'API (comme les tests d'intégration) beaucoup plus tôt qu'avec d'autres méthodes de données de test.
Voici quelques autres avantages de cette approche:
- Comme il ne nécessite pas d'infrastructure de base de données sous-jacente, il peut généralement s'exécuter localement sur les postes de travail des développeurs et des testeurs.
- Les environnements de test isolés uniques à chaque testeur signifient qu'il n'y a pas de collisions de données ou de préoccupations concernant l'intégrité des données pour une base de données de test partagée. Les tests deviennent hautement parallèles, supprimant le temps d'attente et les cycles inutiles des approches traditionnelles.
- Les testeurs peuvent facilement couvrir les cas de coin qui pourraient causer la corruption et d'autres problèmes, sur une base de données de test. Étant donné que chaque environnement de test est isolé, les testeurs peuvent facilement effectuer des tests destructifs, de performance et de sécurité, sans se soucier de l'intégrité d'une ressource partagée.
- Il est facile de partager des tests et des données au sein de l'équipe pour éviter la duplication des efforts, et les tests d'API sont personnalisables à d'autres fins telles que les tests de sécurité et de performance.
- L'utilisation de serveurs virtualisés élimine la complexité du schéma de base de données sous-jacent. Test avec état est disponible pour fournir des scénarios réalistes.
- En capturant uniquement les données dont vous avez besoin avec le masquage dynamique, vous n'avez plus besoin d'une base de données clonée, en plaçant l'accent des tests d'intégration sur les API, plutôt que de maintenir une base de données clonée partagée.
Les tests sur la base de données physique seront toujours nécessaires mais uniquement requis vers la fin du processus de livraison du logiciel lorsque l'ensemble du système sera disponible. Cette approche pour tester les données n'élimine pas entièrement le besoin de tester par rapport à la base de données réelle, mais réduit la dépendance à l'égard de la base de données dans les premières étapes du processus de développement logiciel pour accélérer les tests fonctionnels.
Résumé
Les approches traditionnelles de test de la gestion des données pour les logiciels d'entreprise reposent sur le clonage des bases de données de production et de leur infrastructure, ce qui entraîne des problèmes de coût, de confidentialité et de sécurité. Ces approches ne sont pas évolutives et entraînent un gaspillage de ressources de test. Parasoft's solution de données de test virtuelles met de nouveau l'accent sur les tests et la reconfiguration à la demande des données de test, ce qui permet des tests d'intégration en parallèle qui quittent cette étape critique des tests.



